What is a Partitioning
Basically, you take a single Database instance and chop up big tables into smaller, more manageable pieces. These pieces are called partitions, and you decide how to chop them up using a partitioning key – this could be a date, a region, DOB, or whatever data field makes sense for your setup. It is a way of organizing your database, specifically within that single instance. Think of it like having a massive filing cabinet (your database table) and dividing it into smaller, labeled drawers (partitions) – it's all still in the same cabinet (the same database instance), just better organized.
The main reasons to do this are for better query performance on large tables and to make the database easier to manage. When you run a query, the database can often figure out it only needs to look in a few specific partitions instead of scanning the whole giant table (this is often called "partition pruning"), which is much faster. Managing these smaller chunks is also a win for things like backing up data, archiving old stuff, or rebuilding indexes on just one part at a time. Common ways to set up these partitions are by a range of values (e.g., all January data in one partition, February in another), a list of specific values, or by using a hash of the key. Crucially, all these partitions live on the same database server.
What is Sharding
Sharding is when you take your entire database and spread it out across multiple database instances, which are usually running on different physical servers. This is horizontal scaling in action. Each of these separate database instances becomes a 'shard'. You'll use a sharding key, which is a specific field in your data (like user_id or region_code). The value of this sharding key for any given piece of data determines which shard that data will live on and, consequently, from which shard it will be retrieved. So, data for users A-M might be on Shard 1, and users N-Z on Shard 2.
The big idea here is to scale your database beyond the capacity of a single server – meaning you can handle more data, more reads, and more writes than one machine could ever dream of. Because data is spread out, you'll need some kind of routing mechanism (like a dedicated query router, a proxy, or logic built into your application) to direct incoming operations to the correct shard. Sharding is definitely more complex to set up and manage than partitioning because you're juggling multiple servers. This introduces challenges like how to handle queries that need data from different shards, ensuring data consistency across them, and managing what happens when one shard fails.
Partitioning VS Sharding
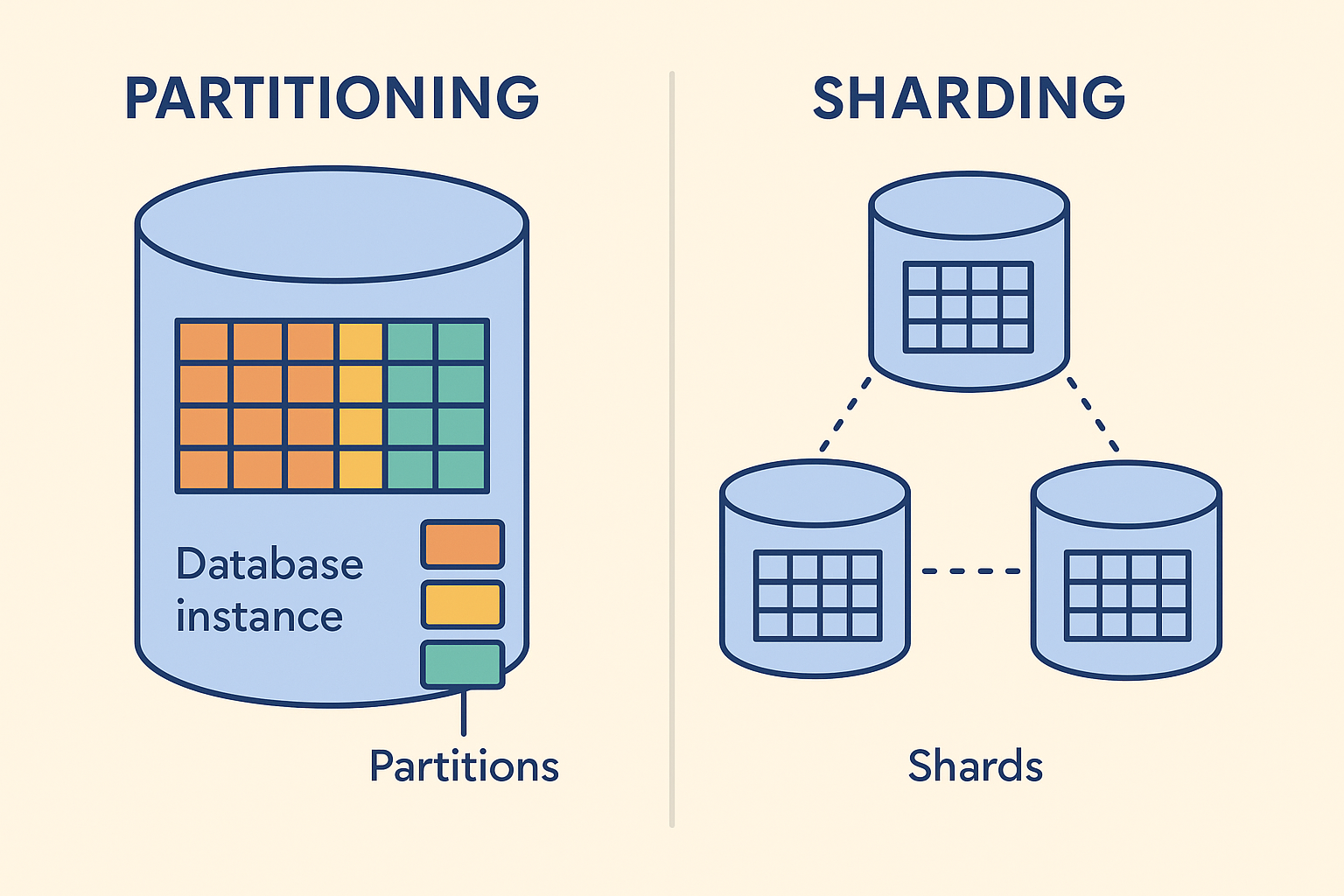 So, these two sound a bit alike, but they're used for different main reasons and work differently under the hood.
So, these two sound a bit alike, but they're used for different main reasons and work differently under the hood.
When you're talking about Partitioning:
- Scope & Data Location: It all happens within one single database instance on one server. The data is logically divided, but it all lives in the same place physically.
- Management: This is mostly handled internally by the database engine itself (like PostgreSQL or SQL Server).
- Complexity: Generally simpler to implement and manage than sharding.
- Purpose: The main goals are to boost query performance on very large tables and improve manageability (like making backups, archiving, or index maintenance easier and faster on those large tables).
- Hardware: You're working with the resources of your existing single server.
- Failure Impact: If that single database server goes down, all your partitions (and thus all that data) become unavailable.
- Application Awareness: Often, your application doesn't even need to know partitioning is happening; it can be transparent.
- Example: PostgreSQL using its built-in features to partition a large
sales_historytable bysale_date.
Now, for Sharding:
- Scope & Data Location: This involves spreading your data across multiple database instances, and these instances are typically on different physical servers.
- Management: This requires much more infrastructure-level coordination. You're not just relying on the DB engine; you often need external tools, routing layers, and careful planning for how the shards interact.
- Complexity: Significantly more complex. You have to deal with request routing to the correct shard, handling potential failures of individual shards, ensuring data consistency (which can be very tricky for transactions across shards), and figuring out how to do operations (like joins) that might need data from multiple shards.
- Purpose: The primary drivers are horizontal scalability (to handle massive amounts of data and high transaction volumes that a single server can't) and fault isolation (if one shard goes down, the other shards can often remain operational, keeping part of your system alive).
- Hardware: You are explicitly using multiple servers.
- Failure Impact: If one shard fails, only the data on that specific shard is directly affected. Other shards (and the data they hold) can continue to operate, potentially offering higher availability for parts of your application.
- Application Awareness: Your application, or a routing layer in front of it, usually needs to be aware of the sharding scheme to direct queries to the correct shard.
- Example: A MongoDB cluster distributing user data across several shard servers based on a hashed
user_id.
It's also worth knowing that these aren't mutually exclusive. You can absolutely have a sharded database system where each individual shard is also internally partitioned to get the best of both worlds – performance and manageability within a shard, and massive scale across shards.